If you are an IT Infrastructure professional living in the Amsterdam or London area creating dual data center setups is probably something you have done or been wanting to do before. The general availability of (dark) fiber connections between data centers makes it normal to at least review the options for having such a setup.
The easy part is usually creating a level 2 network between the two sites, which nowadays can be had at 100GbE or 40GbE just as easy as 10GbE. Basically all you need is two or more Ethernet switches and a few Long Range optics and you are set.
In the case of Amsterdam or London, finding two data centers owned by two different companies at reasonable distance is not hard to do. And it is even easier to find an affordable fiber-provider to interconnect the two. It might surprise you, but in some cases it may prove to be cheaper to rent two racks in two separate lower priced data centers with dark-fiber interconnect than to have two racks next to each other in one of the higher end data centers.
Map of Datacenters in The Netherlands:
So you create a project spreadsheet and put in all the costs for a 3 or 5 year deployment in case of a single data center deployment and in the case of a dual data center deployment. Next to the switches you of course add your servers, virtualization software, routers and firewalls. And then you come to the storage part of your setup.
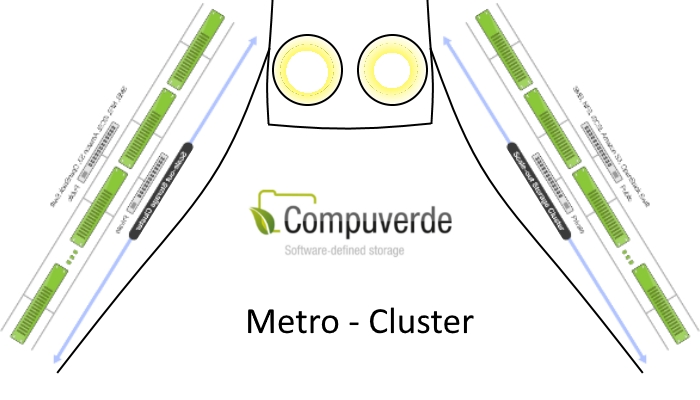
When you have a single data center setup you can use a high availability storage deployment that utilizes a shared SAS bus and you can place your data on mirrors spread over pairs JBOD’s spread over your two racks. In the dual data center setup that does not work very well and you have to use something that is called Metro Cluster. It involves using SAS to Ethernet bridges, you need to double your storage controllers and in most cases you are confronted by a huge uplift in support fee for your storage product.
Metro Cluster: A clustered set of storage stretched over a metropolitan area.
After doing all these calculations it turns out to be more expensive to have a dual data center setup even though, costs for data centers and interconnect are the same or even lower than using a tier one data center with two racks. And the difference is in the storage costs. After doing all these calculations it turns out to be more expensive to have a dual data center setup even though, costs for data centers and interconnect are the same or even lower than using a tier one data center with two racks. And the difference is in the storage costs.
You could of course use two somewhat more simple storage solutions in both data centers and replicate them ‘near real-time’ using software like Zerto or Veeam, but that is not the same as a synchronous solution.

Now Compuverde, software defined storage from Sweden, has released the new Metro Cluster functionality that fixes all of this.
In normal operation, Compuverde is already a scale-out solution that works with a proprietary object store as a basis. With fully supported erasure coding you can achieve a storage efficiency of more than 80% while being able to come with a dual node failure. This means that, for example, when you have 10 storage nodes that each contain 10 drives of 10TB giving you 100TB of storage per node and you use 8+2 erasure coding you can actually use 800TB of your storage for storing data. And with Compuverde you do not need to worry about not filling up your storage, since the impact on performance of filling it up almost completely is really low.
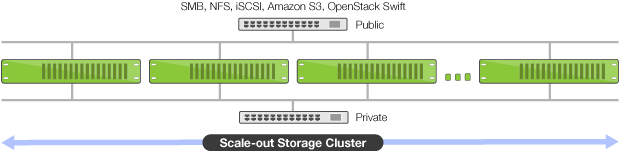
One of the nice things with Compuverde is that you can deploy it so-called hyper converged, which means that you run your storage from the same servers that run your VM’s. There are a few advantages to this approach. The first one is that your storage is nearer to your VM, which will improve the latency to your storage significantly and it will make reads that come from local storage blazingly fast. The second advantage is that you do not have to buy separate storage servers to house your SSD and Hard Drive storage since you fit them in to the same chassis. That saves you power and space in your rack.
The new metro cluster functionality that has been added to Compuverde can use all of these advantages and adds one more. With metro cluster you can use two stacks of Compuverde storage nodes, and let them replicate between two locations. All you need to do this is an IGMP enabled Ethernet that spans between the two locations with a latency of less than 5 miliseconds and a Compuverde license. Setting it up is as easy as deploying a Compuverde cluster (which can be done in just a few minutes if you are good at it) and assigning the metro cluster role to the nodes you want to participate in the metro cluster.
Dear reader, I can almost hear you think: ‘All this text and then only a few lines that say how easy metro cluster actually is. What is all the fuss about?’ Well that is exactly the point. With Compuverde you get a unified storage system, with a virtual file system can spans between two data centers at the same price you would use it in the same data center.
To give you a better idea of what it can do I will describe a typical high performance scenario:
We have 2 data centers that are just under 10KM distance from each other (in fiber length) that have a redundant fiber ring that interconnects them. In each data center we have a single 19” rack of 42HE high. The fibers are coming into the data centers in two different meet-me rooms and are coming to the racks over a different path.
In each data center we place two Mellanox SN2100 half-width 16 port non-blocking 100GbE Ethernet switches that will fit in 1U top of rack. These switches are interconnected by two 100GbE cables in the data center and each switch contains one long range 100GbE LinkX optic that can bridge the 10km at 100GbE using 4 channels of LAN WDM. With that we create a redundant 100GbE Ethernet between the two data centers that supports IGMP. It leaves us with 13 redundant 100GbE ports in each data center.
Next to that we add 3 management nodes of 1U to each rack that have a more modest Intel E5-2620 v4 CPU with 4x32GB DDR4 ECC REG ram, a SATA SSD of 200GB for booting and 4x 2TB SanDisk SATA SSD. Each of these hosts will be connected to both Mellanox switches by using a dual port 10GbE ConnectX-3 network adapter and a 40GbE to 4x10GbE cable. These nodes will use a Xen based hypervisor based on an open source Linux distribution. Two of the 10GbE cables will go to a juniper MX40 router in each data center that will take care of routing and firewalling.
 In total this will give us a raw capacity of 2DC * 12 servers * 10 SSD * 1.6TB = 384TB for the production cluster and 2DC x 3 servers x 4 SSD * 2TB = 48TB for the management cluster.
In total this will give us a raw capacity of 2DC * 12 servers * 10 SSD * 1.6TB = 384TB for the production cluster and 2DC x 3 servers x 4 SSD * 2TB = 48TB for the management cluster.
We could use the entire setup in an active-active way. For this we create a Compuverde cluster of 12 nodes for each data center. To do this we install Compuverde hyper converged. So each physical VMWare ESXi node will have a VM of 32GB of RAM and two virtual CPU cores that has the SAS HBA connected to the VM using VT-D. So now we have 24 virtual Compuverde nodes with each node having 16TB of high performance, high endurance 12Gbit/s SAS3 SSD storage.
In each data center we configure all 12 nodes in metro cluster configuration. With this we will lose 50% of our raw capacity due to the required redundancy between the two data centers. On remaining 12 VM worth of storage we apply a 10+2 erasure coding which will result in an efficiency of 83%. This will lead to a total efficiency of 83% of 50% which is 41.5% so of that 384TB about 160TB can actually be used to store data. On the compute side of it all you can of course only use a maximum of 50% of all available RAM and CPU to survive a complete data center failure. So that is ‘only’ 6TB of RAM and 240 physical (not hyper threaded) CPU cores.
In normal operation you can write to the storage layer synchronously on both sides. Which means that you can use VMWare’s vMotion feature to move a VM from one data center to the other without the need for storage vMotion. You can also use the virtual file system layer feature to write files to the storage cluster using the SMB protocol from both sides at the same time. This will mean that if you have for example a VDI farm running on these hypervisors you can start VDI VM’s on both sides at the same time accessing the same data.
This way you have a very resilient setup, let’s look at a few normal failure scenarios and how you can handle them with this setup:
- A complete node fails: VMWare HA can restart the VM’s on any other node, storage will still be available. Compuverde will rebuild the data that was on the storage VM in that particular node over the available nodes on both sides.
- A switch fails: The connection between the data centers will still be available. All production nodes in the DC where that switch has failed will have only one 100GbE link to the switch left.
- A SSD drive fails: Compuverde will rebuild the data that was on that drive to other drives in the cluster.
- power supply fails: redundant power will still be sufficient to keep the node running.
- A power feed fails: redundant power will still be sufficient to keep all nodes running.
All of these failures are fine and would also survive a single data center setup.

Now let’s look a few disaster failure scenarios and how you can handle those with this setup:
- A data center completely loses power for a few seconds: VMWare HA can restart the VM’s on the data center that has not lost power. After all VMWare boxes have been properly started again the storage will automatically be rebuilt from the storage nodes on the surviving side after which the VM’s running on the surviving side can be moved back to the problem data center using vMotion.
- A data center gets flooded or burns down: VMWare HA can restart the VM’s on the data center that is still surviving. All data will still be redundantly stored using the 10+2 erasure coding scheme so you can still handle two additional node-failures. After rebuilding the failed data center or interconnecting a different data center you can add the newly created storage nodes to the cluster, Compuverde will automatically re-replicate all data and you can the VM’s can be moved to the new data center using vMotion.
So using Compuverde metro cluster setup you can have a Recovery Time Objective of just a few minutes, even when a complete data center fails. Your Recovery Point Objective, from a storage perspective, is 0 seconds. Since all data is written to your metro clustered storage consistently. From an application perspective the Recovery Point Objective will probably be a few seconds. This means that you can have single-VM availability that was previously only achievable using redundantly setup applications.
And the best part of it all: Even in a hyper converged setup using all flash in a metro cluster setup the Compuverde solution with HGST enterprise SSD devices has a lower total cost of ownership than spindle based metro cluster deployments of all currently available options.
Another scenario that is very interesting is for using Petabyte size storage clusters in a metro-cluster setup which completely eliminate the need for third party disaster recovery solutions. This is especially interesting for Medical and Research data that needs to be kept available for a very long time (patient life-time +5 years). But that deserves a separate article.
For more information about Compuverde Metro Cluster or Compuverde in general, contact us. We are more than happy to provide you with more detailed information.
You can reach us by phone on +31 88 46 77 683 or via e-mail at sales@inprove.nl